
引言
训练一个分类器
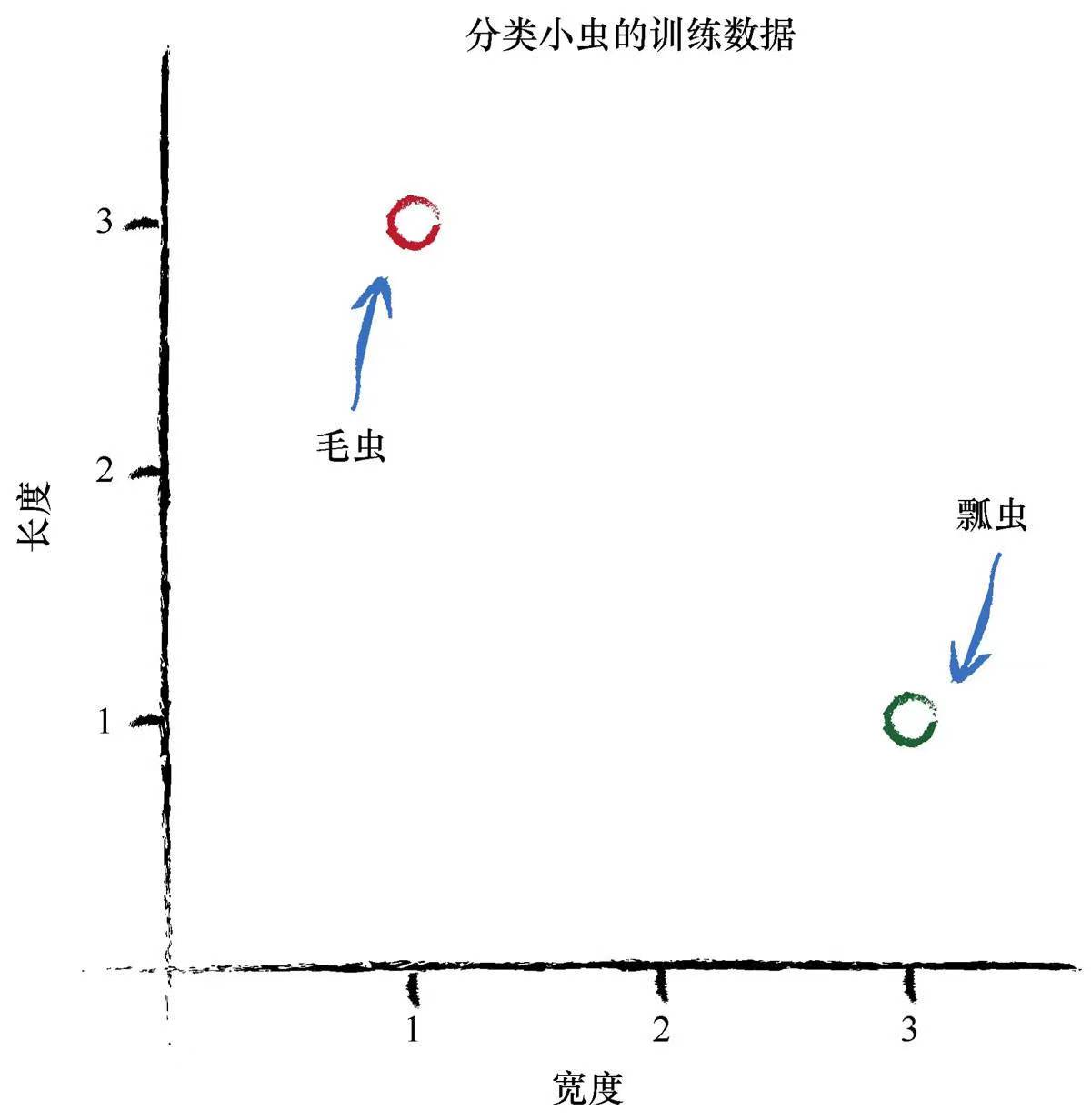
问题:如下,给出一组数组,要求给出一个线性分类器,使它能够较好的对瓢虫和毛虫进行分类

分析:如下图,该问题其实是要求我们求出一条直线来把毛虫和瓢虫“划分”开,因此我们可以设定该直线为
y=Ax
其中x表示宽度,y表示长度,则问题转化为根据已知数据求出参数A,使得该直线能够适当的对毛虫和瓢虫进行划分。
初始时,我们设定A=0.25,则y=0.25x,如下图所示

针对第一个数据,x=3.0,则y=0.25*3.0=0.75,此时易知0.75<1.0,因此我们需要对参数A进行调整,调整的依据是我们得到的误差
误差值=期望目标值-真实输出值
即E=1.1-0.75=0.35
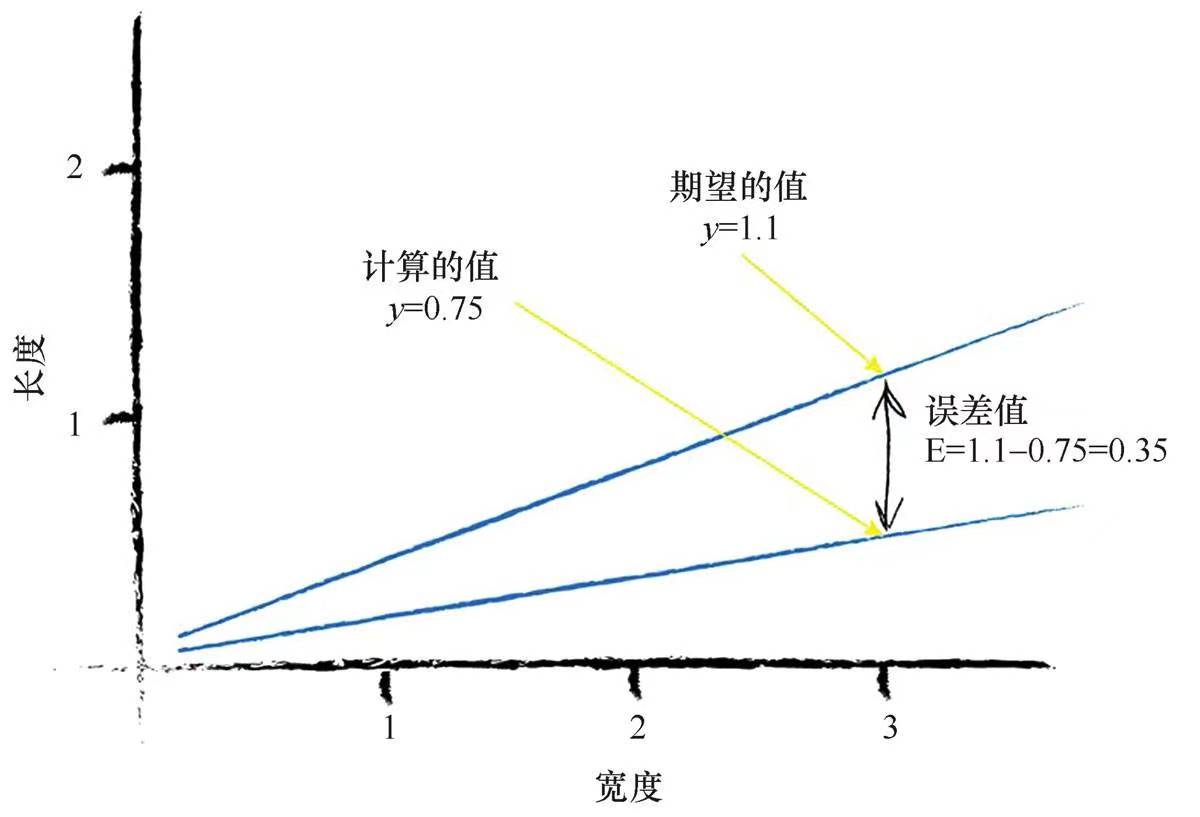
注意,之所以期望目标值设定为1.1而不是原始数据的1.0,是因为我们希望的是得到的直线是将两个数据进行划分,而不是让直线落在数据上。
根据误差定义,我们有
E=t-y=(A+ΔA)x-Ax=(ΔA)x
则:
ΔA=E/X
根据上式我们就可以对斜率进行更新,即当E=0.35,x=3.0时
ΔA=0.35/3.0=0.1167
故更新后的A=0.25+0.1167=0.3367
此时我们便根据第一个样本数据对参数A进行了更新,这就是基于误差调整参数的方法
接下来我们训练第二个样本数据,使用第一个样本训练的A,我们有y=0.3367x,带入第二个样本数据x=1.0.得到y=0.3367,易知此时的真实值与目标值3.0相去甚远,基于此前方法,我们又得到了一个误差,并基于同样的办法对参数A进行更新,我们将目标值设定为2.9,同时误差为E=2.9-0.3367=2.5333,则ΔA=2.5333/1.0=2.5333,于是再次得到更新后的A=0.3367+2.5333=2.9.如下图:

上述过程其实就是针对一个问题通过样本数据对参数进行训练的过程,但同时也易知,最终改的直线不会顾及所有先前的训练样本,而是抛弃了所有先前的训练样本的学习结果,只是对最近的一个实例进行了学习
要解决上述问题,我们只需要引入一个学习率的概念,让参数的训练进行适度改进,而不是猛烈改进。如下,我们设定学习率为L,则
ΔA=L(E/x)
当我们设定L=0.5,重新进行一遍上述针对参数的训练更新过程,则有

正向传播信号
引言中训练一个分类器的实例其实就是一个进行机器学习的实例,在这个实例中,我们采用的核心思想是:基于误差对参数进行训练更新,而为了使得训练过程中所有数据都有效,我们引入了学习率的概念。事实上,在真实的机器学习过程中,如果学习率设置的过大,会导致欠拟合现象,有时还会导致误差迭代不收敛的情况,而如果学习率设置的太小,又会导致迭代次数和频率太多,浪费了大量的资源和精力。关于迭代与学习率的问题,我们会在下文详细阐述,这里我们只做一个引述。
现在,我们将目光放到神经网络上。
神经网络与激活函数
所谓神经网络,即科学家模拟大脑神经对外界事务的学习处理过程提出的一种让机器对客观世界事物进行自学习的方法。
如下图所示,在大脑中存在许许多多这样的神经元,他们负责传递在大脑中流转的电信号,只有当电信号输入到一个神经元时。只有它的强度达到一个程度才能使得神经元将该信号向下一个神经元进行传递,在传递过程中神经元还会对电信号进行一些处理才将处理后的信号进行输出。
[ ]
]
上述过程有两个重要步骤,即:
- 输入信号只有达到一定强度时,才能激发神经元对信号进行传递输出
- 传入的信号需要通过神经元的处理后再向下传递
针对上述第一个问题,科学家设计一种名为激活函数的式子来模拟这个过程,其中较为经典的激活函数就是sigmoid函数,也称逻辑函数和S函数。如下图所示:

其表达式为:

至此,我们对神经元的信号传递模拟可以用下图进行直观感受:


在此基础上,科学家便设计出了神经网络模型,我们以经典的三层网络模型进行示例,其中每一层有三个神经元或节点如下图所示:
同时,模拟神经元对信号的传递和处理过程,科学家在上述神经网络中加入了链接权重,即对每一组输入数据,在达到激活条件后,需要重新对数据进行分配后再传入下一层,其中较小的权重将弱化信号,而较大的权重将放大信号,而如果权重为0,则表示该链接是被断开了。如下图所示:
网络信号传递实例
我们用一个两层的网络模型来阐述信号在神经网络中是如何进行传递的
如图所示,我们有两个输入值1.0和0.5,这两个输入值分别通过第一层的两个节点进行传入,同时我们设定好信号向后传递的权重参数w1,1=0.9,w1,2=0.2,w2,1=0.3,w2,2=0.8(注意,第一层的神经元我们不设置激活函数)。如下图所示:

则经过权重调整后,进入第二层的两个输入信号分别为:
x1=1.0*0.9+0.5*0.3=1.05
x2=1.0*0.2+0.5*0.8=0.6
第二层对上述两个传入的输入信号再通过激活函数(y=1/(1+e^-x^))进行调整,得到:
y1=1/(1+0.3499)=0.7408
y2=1/(1+0.5488)=0.6457
在第二层的信号计算过程如下图所示

最终输入信号在整个网络中的信号传递过程如下图所示:

使用矩阵乘法的三层网络实例
我们重新设定一个三层网络模型,每层都有三个神经元节点,其中我们将第一层称之为输入层,第二层称之为隐藏层,第三层称之为输出层。同时我们将计算过程转换为矩阵进行计算,来再次感受神经网络信号传递过程。如下图所示:

我们将输入信号的三个值进行矩阵表示:
I=[0.9,0.1,0.8]
同时用winput_hidden表示输入层到隐藏层之间的权重矩阵:
winput_hidden=[0.9 0.3 0.4
0.2 0.8 0.2
0.1 0.5 0.6]
用whidden_output表示输入层到隐藏层之间的权重矩阵:
whidden_output=[0.3 0.7 0.5
0.6 0.5 0.2
0.8 0.1 0.9]
则信号到达隐藏层的输入为:

如今的传递状态为:

至此,我们需要对传入隐藏层的信号进行激活处理,即Ohidden=sigmoid(Xhidden):

得到此时的信号传递状态图:

接下来对信号的传递过程如上述计算过程继续,
计算输出层的输入信号:

输出层对信号进行激活处理:

完整信号传递过程为:

反向传播误差
至此,我们已经根据神经网络模型完成了数据从输入到输出的全过程。现在让我们重新会想起引言中的分类器实例,我们针对输入信号得到输出信号时,最终得到的结果不一定是满足我们的要求的,换句话说,我们得到是输出信息与我们的期望值有一定误差,接下来我们需要根据这个误差对我们的参数进行调整,使得网络模型能够对输入信号转换出我们期望的输出。在分类器实例中我们训练和更新的参数是斜率A,而在神经网络模型中我们需要进行训练和调整的参数则是网络传播的链接矩阵,即上述示例中的Winput_hidden和Whidden_output。
在对参数进行修正和训练之前,我们现在需要解决一个问题,那就是虽然我们得到了输出层的误差,但却不知道隐藏层的误差。针对隐藏层的误差如何得来,我们可以通过输出层误差,并根据权重矩阵对隐藏层误差进行反向传播。
如下图所示,我们重新设定一个三层网络模型来进行说明:

设输出层误差为:

则我们根据Whidden_output来反向计算隐藏层的误差:

为使矩阵计算方便,我们舍去分母:

这样做的原因是,较大的权重就意味着携带较多的输出误差给隐藏层。这是非常重要的一点。这些分数的分母是一种归一化因子。如果我们忽略了这个因子,那么我们仅仅失去后馈误差的大小。也就是说,我们使用简单得多的e1* w1,1来代替e1* w1,1/ ( w1,1+w2,1)。
最终我们得到反向传播误差的矩阵式子为:

权重更新
得到各层之间的误差后,我们就可以对链接权重进行更新。一直以来,如何对权重进行更新曾困扰科学界多年,因为对于层次比较多的网络模型来说,普通的更新方法将耗费巨大的计算量,直到20世纪60年代到70年代,有人提出了一种切实可行的办法。接下来让我们介绍梯度下降法。
梯度下降法
我们来看一个最优化问题,比如有一个表达式为g(x)=(x-1)^2^的二次函数,它的最小值是g(x)=0,出现在x=1时。
现在假如x=3,我们要在此基础上求出当g(x)取得最小值时x的值,而为了使g(x)变小,我们需要将x向左移动,也就是减小x,同理假如x=-1时,我们需要将x向右移动,通过观察图像发现,我们的移动方向刚好和g(x)在该点处的导数符号相反。如下图所示:

此外,我们还需要解决的问题是,移动的步幅需要多大?
在梯度下降法中,我们根据g(x)在该点处的梯度大小来决定每次移动的步幅,而为了防止出现在引言分类器示例中出现的现象,我们同时对步幅发调整加了学习率。则整个过程用一个表达式来表示就是:

此外,学习率的大小也将决定收敛速度,如果设置不当甚至会出现不收敛的情况。如我们设置上式η=1,从x=3开始迭代,我们会发现每次迭代是在-1和3之间循环往复出现的,这样我们将永远无法迭代到最小值。

综上,我们将整个迭代过程通过图解表示如下:

神经网络中的梯度下降
损失函数
在梯度下降法中,我们通过梯度的大小和方向来确定当函数取得最小值时自变量的值。而在神经网络中,我们要求的是当误差函数取得最小时对应参数值。我们称这个误差函数为损失函数,其因变量即是误差,自变量即是参数,如果有多个参数,则对应的图像也应该是高维的。
在对损失函数使用梯度下降法时,我们需要明确以下问题
- 在使用梯度下降法时,每次迭代的步幅大小有函数在该点处的梯度大小决定,因此我们最好保证当距离最低点较远时步幅较大,越靠近最低点时,迭代的步幅大小应该尽量保持越小,以避免过度迭代,从而跳过最低但
- 在最低点处的梯度是存在的,即可导,因此我们尽量避免使用绝对值函数
- 当函数出现多个最低点(此时称为极小值)时,为保证结果的正确,我们应尽量多设置几个初始值进行多次尝试迭代
权重更新表达式推导
由梯度下降法表达式及思想知,关键因素是我们要求出损失函数对权重参数的导数,即:

由链式法则得:

故有:


而S函数的微分结果为:

因此整个表达式的微分结果为:

为使表达式简洁,我们得到:

最终推导出的整个权重更新式子为:

其中α即我们上文中表述的学习率。
相关问题探讨
输入数据

由权重更新表达式可知,权重的改变依赖于激活函数的梯度和输入信号Oj
其中
- 小梯度意味着限制神经网络学习的能力。这就是所谓的饱和神经网络。这意味着,我们应该尽量保持小的输入。
- 我们也不应该让输入信号太小。当计算机处理非常小或非常大的数字时,可能会丧失精度,因此,使用非常小的值也会出现问题。输入0会将oj设置为0,这样权重更新表达式就会等于0,从而造成学习能力的丧失,因此在某些情况下,我们会将此输入加上一个小小的偏移,如0.01,避免输入0带来麻烦。
输出数据
同样由激活函数知,最终数据经过激活函数后,其输出极限为1,因此我们的期望值不能设置超过1的数据,否则误差太大,导致训练网络得到更大的权重,由上述知,越大的权重将在下一场训练中造成网络饱和问题。
因此,我们应该重新调整目标值,匹配激活函数的可能输出,注意避开激活函数不可能达到的值。虽然,常见的使用范围为0.0~1.0,但是由于0.0和1.0这两个数也不可能是目标值,并且有驱动产生过大的权重的风险,因此一些人也使用0.01~0.99的范围。
随机初始权重
在初始权重的设置上,数学家所得到的经验规则是,我们可以在一个节点传入链接数量平方根倒数的大致范围内随机采样,初始化权重。因此,如果每个节点具有3条传入链接,那么初始权重的范围应该在从-1 /sqrt(3)到+1/sqrt(3),即±0.577之间。如果每个节点具有100条传入链接,那么权重的范围应该在-1/sqrt(100)至+1/sqrt(100),即±0.1之间。
这一经验法则实际上讲的是,从均值为0、标准方差等于节点传入链接数量平方根倒数的正态分布中进行采样。
禁止将初始权重设定为相同的恒定值,特别是禁止将初始权重设定为0。
综上有:
如果输入、输出和初始权重数据的准备与网络设计和实际求解的问题不匹配,那么神经网络并不能很好地工作。
一个常见的问题是饱和。在这个时候,大信号(这有时候是由大权重带来的)导致了应用在信号上的激活函数的斜率变得非常平缓。这降低了神经网络学习到更好权重的能力。
另一个问题是零值信号或零值权重。这也可以使网络丧失学习更好权重的能力。内部链接的权重应该是随机的,值较小,但要避免零值。如果节点的传入链接较多,有一些人会使用相对复杂的规则,如减小这些权重的大小
因此有:
- 输入应该调整到较小值,但不能为零。一个常见的范围为0.01~0.99,或-1.0~1.0,使用哪个范围,取决于是否匹配了问题。
- 输出应该在激活函数能够生成的值的范围内。逻辑S函数是不可能生成小于等于0或大于等于1的值。将训练目标值设置在有效的范围之外,将会驱使产生越来越大的权重,导致网络饱和。一个合适的范围为0.01~0.99。