肤色分割
肤色分割概述
肤色分割技术,即从一幅图片中分割提取出图片中的肤色区域作为后续处理区域。其原理为:根据皮肤的颜色特性来设定阈值,满足该阈值的肤色区域即可判别为肤色区域。其中阈值法的关键是选择一个合适的颜色空间模型表示。目前常用的颜色空间模型主要有RGB颜色空间、HSV颜色空间、YCrCb颜色空间。
色彩空间理论
RGB色彩空间
RGB分别代表英文Red、Green、Blue三个单词的缩写,而物质世界的颜色均可由Red、Green、Blue三种颜色按照不同的比例混合得到,如下图所示,所谓RGB色彩空间模型就是将Red、Green、Blue三种抽象的颜色分别映射到0∼255这个范围的具体数字之间,继而将这三种颜色在三维空间中唯一对应的坐标点视为一种颜色。
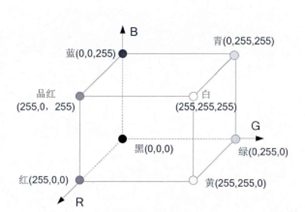
由该颜色模型所表达的物质世界里的任何颜色都与其线性组合的RGB三个颜色分量高度相关,其连续变换并不直观,当我们想要对图像的颜色进行调整时就需要更改三个颜色分量才行。我们知道自然环境容易受光照、遮挡等情况的影响,即物质世界的颜色容易受光照影响,而该模型未考虑到光照因素,一旦亮度变化,真实颜色就会发生变化,这样就对肤色提取造成了一定的困难。
Kovac等人在2003年提出,肤色在RGB色彩空间下可满足以下条件:
均匀光照下:
$$
\left{\begin{array}{c}
R>95, G>40, B>20 \
\max (R, G, B)-\min (R, G, B)>15 \
|R-G|>15 \
R>G \
R>B
\end{array}\right.
$$侧光拍照下:
$$
\left{\begin{array}{c}
R>220, G>210, B>170 \
|R-G| \leq 15 \
R>B \
G>B
\end{array}\right.
$$代码实例
```python
RGB色彩空间肤色检测
def skinRGB(img):
x,y=img.shape[0:2]
skin=np.zeros((x,y),np.uint8)#皮肤掩膜
b,g,r=cv.split(img)#通道分离
for i in range(x):
for j in range(y):
# 均匀光照环境(检测效果较差)
if int(r[i][j])>95 and int(g[i][j])>40 and int(b[i][j])>20 and
max(r[i][j],g[i][j],b[i][j])-min(r[i][j],g[i][j],b[i][j])>15
and abs(int(r[i][j])-int(g[i][j]))>15 and int(r[i][j])>int(g[i][j]) and int(r[i][j])>int(b[i][j]):
skin[i][j]=255
# 侧光环境(全黑)
# if r[i][j]>220 and g[i][j]>210 and b[i][j]>170 and
# abs(int(r[i][j])-int(g[i][j]))<=15 and
# r[i][j]>b[i][j] and g[i][j]>b[i][j]:
# skin[i][j]=255
res=cv.bitwise_and(img,img,mask=skin)
return res
检测结果:
[](https://imgse.com/i/pSIxzQA)
### HSV色彩空间
HSV,即Hue(色调、色相),Saturation(饱和度、色彩纯净度),Value(明度)。如图所示,在该模型中,色调H用角度度量,取值在0°~360°之间,其中红色为0°,按照逆时针旋转,绿色为120°,蓝色为124°;饱和度S指颜色接近光谱色的程度,饱和度越高,颜色就越深且艳,反之颜色就浅且淡,其取值范围为0%∼100%;明度V表示颜色的亮度,其取值同样在0%∼100%之间,其中明度为0%表示亮度为0,则颜色就为黑色,同理明度为100%时颜色就为白色。
在HSV颜色空间中,可将易受光照影响的明度V分量分离出,颜色可由色调H和饱和度S确定。通常我们用如下约束方程来判定一块像素点是否为肤色点:
$$
\left\{\begin{array}{c}
0 \leq H \leq 20 \\
S \geq 48 \\
V \geq 50
\end{array}\right.
$$
#### 代码实例
```python
# HSV色彩空间肤色检测
def skinHSV(img):
x,y=img.shape[0:2]
skin=np.zeros((x,y),np.uint8)
hsv=cv.cvtColor(img,cv.COLOR_BGR2HSV)
h,s,v=cv.split(hsv)
for i in range(x):
for j in range(y):
if h[i][j]>=0 and h[i][j]<=20 and s[i][j]>=48 and v[i][j]>=50:
skin[i][j]=255
res=cv.bitwise_and(img,img,mask=skin)
return res
检测结果:
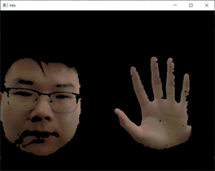
YCrCb色彩空间
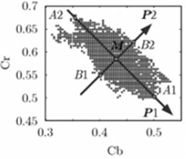
YCrCb,其中Y指亮度,Cr表示亮度与RGB模型中红色分量的差异,Cb表示亮度与RGB模型中蓝色分量的差异。在该模型中,人类的肤色分布在一个由Cr、Cb分量组成的近似平面椭圆上。如图所示,当图像的Cr、Cb分量取值在该椭圆内时,我们就可判定图像的该像素点为肤色点。
代码实例
# HSV色彩空间肤色检测
def skinHSV(img):
x,y=img.shape[0:2]
skin=np.zeros((x,y),np.uint8)
hsv=cv.cvtColor(img,cv.COLOR_BGR2HSV)
h,s,v=cv.split(hsv)
for i in range(x):
for j in range(y):
if h[i][j]>=0 and h[i][j]<=20 and s[i][j]>=48 and v[i][j]>=50:
skin[i][j]=255
res=cv.bitwise_and(img,img,mask=skin)
return res
# 椭圆肤色检测
def skinMaskYCrCb(img):
skinCrCbHist=np.zeros((256,256),np.uint8)#创建一张全黑背景图
# 在图片上绘制椭圆曲线绘制椭圆弧线,-1表示填充,故该函数显示为在图片上绘制一个白色椭圆区域
# 该图像的横纵坐标值分别为cb,cr,椭圆区域内为采集的肤色样本点cb,cr值
cv.ellipse(skinCrCbHist, (113, 155), (23, 25), 43, 0, 360, (255, 255, 255), -1)
# 参数:
# 被绘制的图片
# 轴心坐标
# 长短轴
# 椭圆和水平方向上的旋转夹角
# 椭圆弧相对于水平轴的起始角度
# 椭圆弧相对于水平轴的结束角度
# 椭圆弧的颜色值
# -1表示填充
# 将图像转换到YCrCb颜色空间上
YCrCb=cv.cvtColor(img,cv.COLOR_BGR2YCrCb)
y,cr,cb=cv.split(YCrCb)#通道分离
skin=np.zeros(cr.shape,np.uint8)#创建皮肤掩膜
x,y=cr.shape
for i in range(x):
for j in range(y):
if(skinCrCbHist[cr[i][j],cb[i][j]]>0):#当图像的cr,cb通道值在椭圆区域内,则判定该点即为皮肤像素点
skin[i][j]=255
# 与操作,函数将较小的值作为0,较大的值作为1进行逻辑操作,故黑色区域为黑色,白色区域为原图
res=cv.bitwise_and(img,img,mask=skin)
# cv_show("res",res)
# 图像二值化处理
return res
# YCrCb颜色空间的Cr分量+Otsu法阈值分割算法
def SkinMaskYCrCb_ostu(img):
YCrCb=cv.cvtColor(img,cv.COLOR_BGR2YCrCb)
y,cr,cb=cv.split(YCrCb)
_,skin=cv.threshold(cr,0,255,cv.THRESH_BINARY|cv.THRESH_OTSU)
skin=cv.morphologyEx(skin, cv.MORPH_OPEN, kernel=np.ones((3, 3)))
# cr = cv.GaussianBlur(cr, (3, 3), 0)
res=cv.bitwise_and(img,img,mask=skin)
return res
图像二值化
在计算机中,彩色图像由多维矩阵构成,如RGB彩色图像由三维矩阵构成,每个维度分别代表图像的长宽和色彩通道,然而当我们对图像中的肤色区域进行提取之后,我们就对图像的色彩不感兴趣了,而这些色彩等信息会加大我们下一步对图像处理的工作量,因此一般情况下我们对图像进行处理时需要将图像转换为灰度图,灰度图在计算机中存储时是一个一维矩阵,矩阵中的数字大小代表了图像的灰度,其范围在0∼255之间,其中0代表纯黑色,255代表纯白色。
所谓图像二值化即将灰度图像转换为黑白图像。图像二值化是为了进一步分离出我们感兴趣的区域与背景图像部分,并且通过二值化后的图像可以更加清晰的观察到图像的噪点及不光滑的部分。目前实现图像二值化的方法主要有两种,即固定阈值法和自适应阈值法。固定阈值法就是手动设置一个阈值,当图像的像素点大于该阈值时我们就将该像素点置为黑色(或白色),反之则置为白色(或黑色)。
自适应阈值法即是根据图像整体的某一特征来自动设置该图像的阈值,相比于固定阈值法,自适应阈值法具有较好的灵活性。目前较好的自适应阈值法是由日本学者大津年提出的最大类间方差法,简称OTSU[7]。其原理为根据图像的灰度值的不同,将图像分割成背景和目标两大部分,构成图像的两部分之间的差别用背景和目标之间的方差表示。
设图像为I(x,y),目标区域和背景的分割阈值为T,目标像素点数为N0,占图像全体比例为ω0,平均灰度为µ0。背景像素点数为N1,占图像全体比例为ω1,平均灰度为µ1。图像大小为M×N,总平均灰度记作µ,我们称g为类间方差,则有:
$$
\begin{array}{l}
\quad \omega_{0}=N_{0} /(M \times N) \quad \
\quad \omega_{1}=N_{1} /(M \times N) \quad \
\quad N_{0}+N_{1}=M \times N \quad \
\quad \omega_{0}+\omega_{1}=1 \
\quad g=\omega_{0} \left(\mu_{0}-\mu\right)^{2}+\omega_{1} \left(\mu_{1}-\mu\right)^{2}=\omega_{0} \omega_{1}\left(\mu_{0}-\mu_{1}\right)^{2} \
\end{array}
$$
遍历图像使得到类间方差最大的阈值T即为所求。设二值化后图像为B(x,y):
$$
B(x, y)=\left{\begin{array}{ll}
0, & I(x, y)<T \
1, & I(x, y) \geq T
\end{array}\right.
$$
图像形态学处理
通常在二值化处理后的图像中,存在许多小孔和细线等使得图像不光滑的部分,为使图像中的手势部分更加完善并减少下一步图像处理的计算量,我们需要对图像进行形态学处理,形态学处理操作有两种,分别为膨胀操作和腐蚀操作
图像膨胀
所谓图像膨胀,可简单理解为将图像各区域进行向外扩张,运行效果表现为图像的高亮区域比原始图像的高亮区域变的更大,故一般用于去除图像中的“毛刺”。其算法原理为:用适当的卷积核(该核由算法设计者自定义,可为矩形核或十字矩阵核,核内的值全为1,核大小由用户自定义,一般为3×3或5×5)遍历图像,并与原始图像进行与运算,当与运算的结果只要有一个为1,就将核心的像素值置为1,否则置为0。
图像腐蚀
同图像膨胀类似,图像腐蚀可简单理解为将图像的区域进行缩小蚕食,其效果表现为原始图像的高亮部分区域变的更小了,一般用于“锐化”图像高亮部分。其原理为:用适当大小的卷积核(核内各值均为1)遍历图像并与图像进行与运算,当核内运算结果均为1时我们才将核心像素值置为1,否则置为0。
手势提取
最大轮廓面积提取手势
经肤色提取后的图像中存在脸部区域和手势区域,为提取图像中的手势部分去除脸部区域,我们需要使用一定的特征来筛选出图像中的手势,传统图像处理中的特征由图像轮廓周长、图像轮廓面积与图像轮廓外接矩形的长宽比等,在本论文中我们选取图像的轮廓面积作为筛选特征。opencv中的内置函数cv2.findContours可检测出二值化后图像的所有轮廓的位置信息,并返回用户一个轮廓矩阵,得到轮廓矩阵后再使用其内置函数cv2.contourArea来计算各轮廓的面积,并判定面积最大的轮廓区域就是手势区域,很显然,该判定方法需要测试者在视频中的手势区域足够大才能检测到。
代码实例
# 遍历图片轮廓,取轮廓面积最大作为手势轮廓,并返回轮廓及其对应信息
def contours_detect(img):
img_gray=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
_,thresh=cv.threshold(img_gray,127,255,cv.THRESH_BINARY)
#轮廓检测
contours= cv.findContours(thresh, cv.RETR_TREE, cv.CHAIN_APPROX_NONE)[0]
# 遍历轮廓获取轮廓面积
img_area=[]
for i,c in enumerate(contours):
(x,y,w,h)=cv.boundingRect(c)#获取图像轮廓外接矩形位置
area=cv.contourArea(c)#获取轮廓面积
# area=w*h#轮廓外接矩形面积
img_area.append([c,area,(x,y,w,h)])#获取轮廓外接矩形面积,以及对应轮廓信息
img_area=pd.DataFrame(img_area,columns=["cnt","area","location"])#将获取的轮廓面积及其信息转换为DataFrame结构
max_location=np.argmax(img_area['area'], axis=0)#获取最大轮廓面积的索引号
x,y,w,h=img_area.loc[max_location]['location']#获取最大轮廓面积的轮廓信息
cnt=img_area.loc[max_location]['cnt']
# draw_img = img.copy()
# cv.drawContours(draw_img,[cnt],-1,color=(0,0,255),thickness=2)
# img_boundrect = cv.rectangle(draw_img, (x, y), (x + w, y + h), (0, 0, 255), 2)#画出最大轮廓外接矩形
# cv_show("res",img_boundrect)
return cnt,(x,y,w,h)
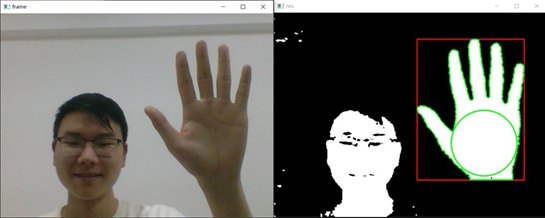
效果如下:

内切圆算法切除手臂
进一步提取出的手势区域中仍然有可能存在手臂部分(当测试者穿短袖或者挽起衣袖时,而这是不可避免的),为此我们需要对可能出现的手臂进行切除,在这里我们使用内切圆算法对手臂部分进行切除。
如图所示,该算法原理为:遍历手势区域内的像素点(实际测试过程中遍历的像素点是手势区域外接矩形内的像素点),计算各点到轮廓的最短距离,记为dist,寻找各dist中的最大值,记为r,并以该max{dist}所对应的像素位置为圆心(图中O点),以r为半径画圆,并作该圆切线与手势轮廓外接矩形ABCD交与MN两点,最后将矩形MNCD区域内的所有像素值置为0,就达到了切除手臂的目的。
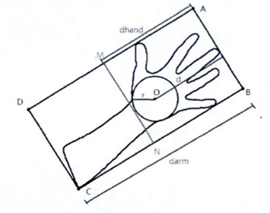
在opencv中,内置函数cv2.pointPolygonTest(cnt,(i,j),True)用于判定某像素点是否在轮廓内部,若在则计算该点距离轮廓最近的距离,我们利用该函数就可计算出上述内切圆半径r和圆心O。测试效果如图2-10所示(为减小误差,测试时切线向下平移了10个像素的位置)。
代码实例
# 手臂分割内切圆算法(无法切出拇指向下的手势),返回切除手臂后的手势轮廓及其对应信息
def handCut(img,cnt,x,y,w,h):
max = 0
point = ()
for i in range(x, x + w):
for j in range(y, y + h):
# 判定某像素点是否在轮廓内部,若在,则计算该点距离轮廓最近的距离
dist = cv.pointPolygonTest(cnt, (i, j), True)
# print(dist)
if dist > max:
max = dist
point = (i, j)
cv.circle(img, point, int(max), (0, 255, 0), 2)
return point,max
def handCount(img):
cnt, (x, y, w, h) = contours_detect(img)#找出皮肤检测出的手势轮廓
# 内切圆算法切除多余的手臂部分
point,r=handCut(img, cnt, x, y, w, h)
img[int(point[1] + r) + 10:y + h, x:x + w] = 0 # 切除多余部分
cnt, (x, y, w, h) = contours_detect(img)#再次计算轮廓
return img,cnt,(x,y,w,h)
效果如下: