
异步加载
AJAX技术介绍
AJAX是Asynchronous JavaScript And XML的首字母缩写,意为异步JavaScript与XML。使用AJAX技术,可以在不刷新网页的情况下更新网页数据。使用AJAX技术的网页,一般会使用HTML编写网页的框架。在打开网页的时候,首先加载的是这个框架。剩下的部分将会在框架加载完成以后再通过JavaScript从后台加载。
使用异步加载技术的网站,被加载的内容是不能在源代码中找到的,因此如果一个网页的文字在源代码中找不到,大多数情况下是使用的AJAX技术
案例分析
打开百度翻译页面
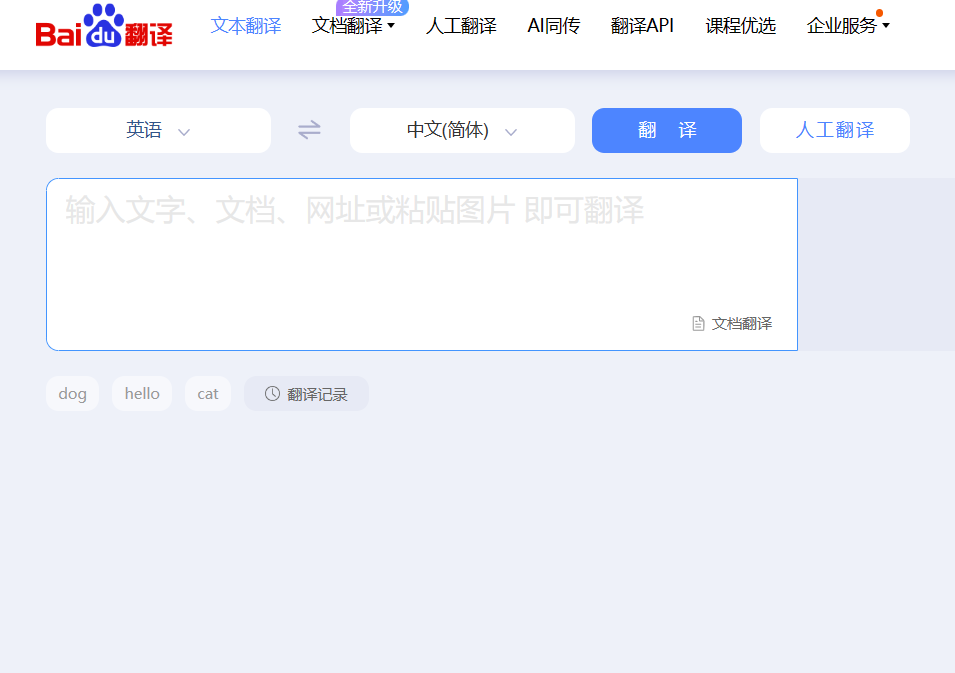
按F12打开抓包工具,当在页面中输入英文(如dog)时,发现页面会进行刷新
点击抓包工具的“network”选项卡,并点击Fetch/XHR选项,则在该选项下方会出现异步加载请求包
分析加载出来的请求包,发现在请求包“sug”中,其请求参数是我们输入的翻译英文“dog”
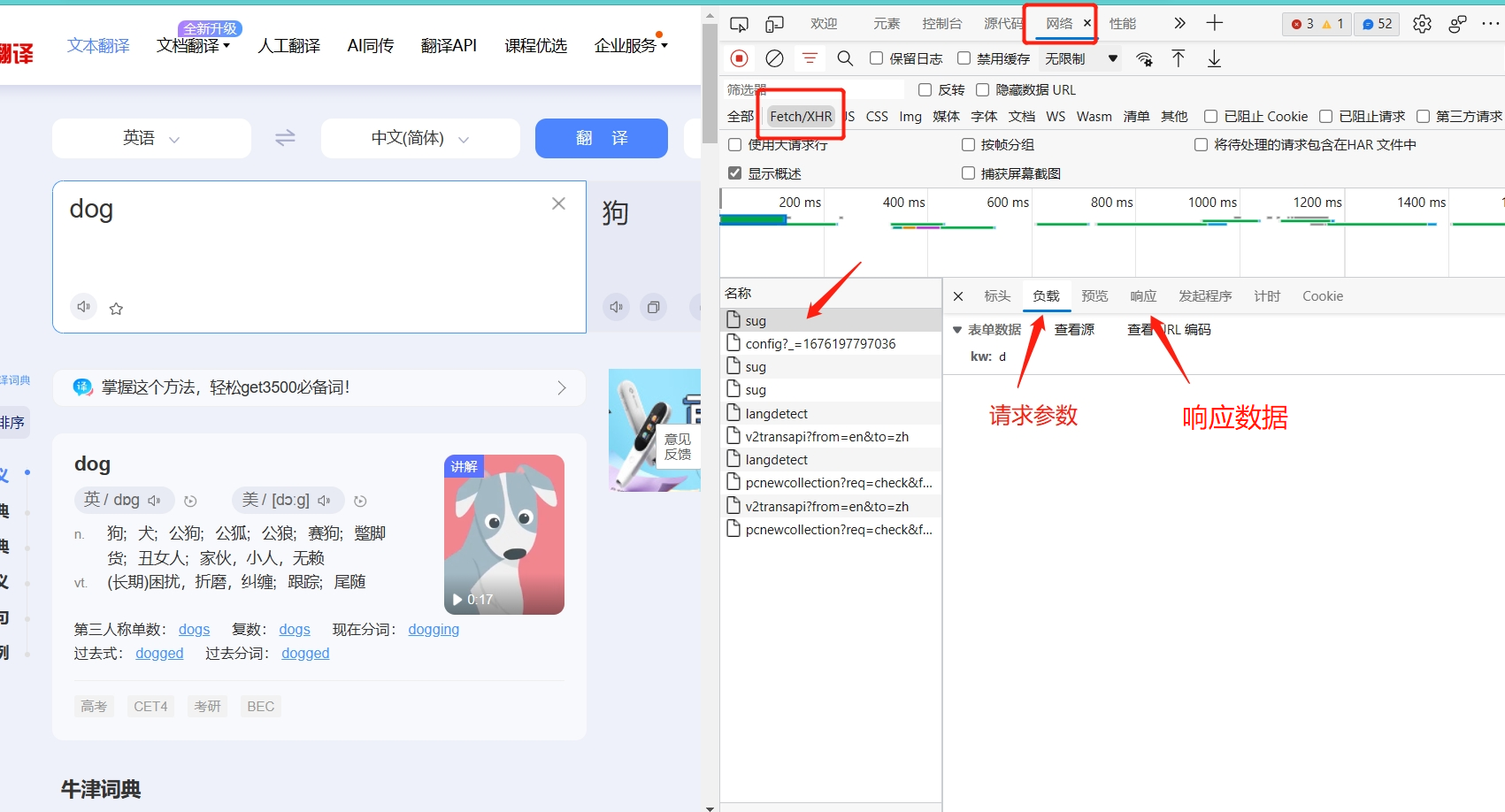
分析请求头,发现该数据包向URLhttps://fanyi.baidu.com/sug请求数据,请求方式为POST,得到的响应数据格式为JSON
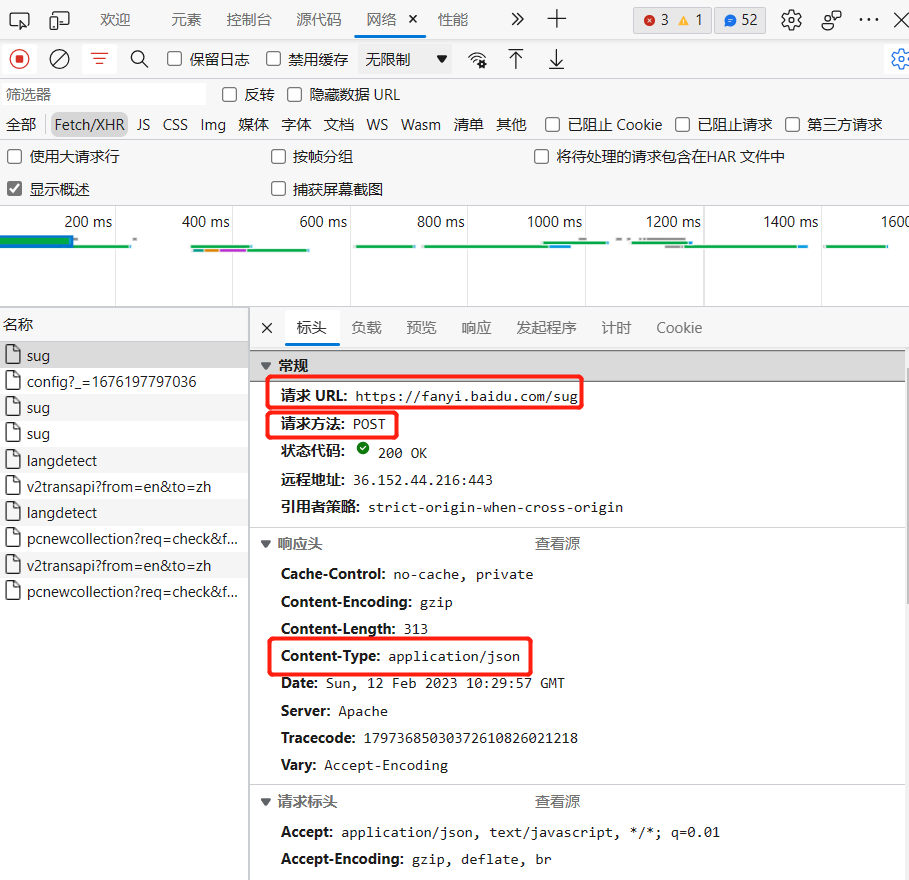
分析响应数据,发现得到的响应数据是JSON格式,尝试对其解析之后,发现得到的数据确实是我们对“dog”英文的翻译结果
上述案例中通过输入请求参数,对服务器发起请求得到响应数据的过程是一种最简单的异步加载方式
在有的网站中,开发者会将数据伪装成json数据放在JS代码中进行渲染,这样我们在看似确实在源代码中找不到想要的数据,因此开发者就制造了一种伪异步加载的效果
除此以外,还有一些网页,显示在页面上的内容要经过多次异步请求才能得到。第1个AJAX请求返回的是第2个请求的参数,第2个请求的返回内容又是第3个请求的参数,只有得到了上一个请求里面的有用信息,才能发起下一个请求。
json格式数据
JSON是一种格式化字符串。JSON字符串与Python的字典或者列表非常相似。
JSON的全称是JavaScript Object Notation,是一种轻量级的数据交换格式。网络之间使用HTTP方式传递数据的时候,绝大多数情况下传递的都是字符串。因此,当需要把Python里面的数据发送给网页或者其他编程语言的时候,可以先将Python的数据转化为JSON格式的字符串,然后将字符串传递给其他语言,其他语言再将JSON格式的字符串转换为它自己的数据格式。
json格式数据其实是一种“中介语言”。举一个例子:一个会英语不会德语的中国人,和一个会英文不会中文的德国人,他们可以使用英语愉快地交谈。英语在他们的交流中扮演了一个中介的角色。JSON在网络通信里面就是这个中介。
观察下述字典:
person = {
'basic_info': {'name': 'kingname',
'age': 24,
'sex': 'male',
'merry': False},
'work_info': {'salary': 99999,
'position': 'engineer',
'department': None}
}
我们可以直接使用json.dumps(person)将字典转换为json格式字符串
使用json.loads(person_json)也可以将json字符串转换为字典或者列表
import json
person_json=json.dumps(person,indent=4)#将字典或者列表、列表字典等字符串转换为json格式,并为其添加4个空格的缩进
person_str=json.loads(person_json)#将json数据转换为字符串
print(person_json)
print(type(person_json))
print(person_str)
案例1:破解百度翻译
# -*- codeing=utf-8 -*-
# @Author:姜磊
# 人间烟火
from lxml import etree
import requests
import json
en=input('请输入您要翻译的英文:')
# 异步加载的url
url='https://fanyi.baidu.com/sug'
# UA伪装
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47'
}
# 发起post请求提交的参数数据
data={'kw':en}
# 通过post方式请求数据,该案例中返回的结果是json格式存储,需要对json格式数据进行解析
res=requests.post(url=url,headers=headers,data=data).json()
print(res['data'])
'''
# 存储翻译结果
fp=open(en+'.json','w',encoding='utf-8')
json.dump(res,fp=fp,ensure_ascii=False)#写入json数据
f=open('hello.json','r',encoding='utf-8')
readJson=json.load(f)#读取json数据
print(readJson)
'''
案例2:抓取乐视视频评论
打开乐视,随意点开一个视频,获取其源代码,通过开发者工具分析页面的异步加载请求,可以发现评论所在的请求在如下图所示
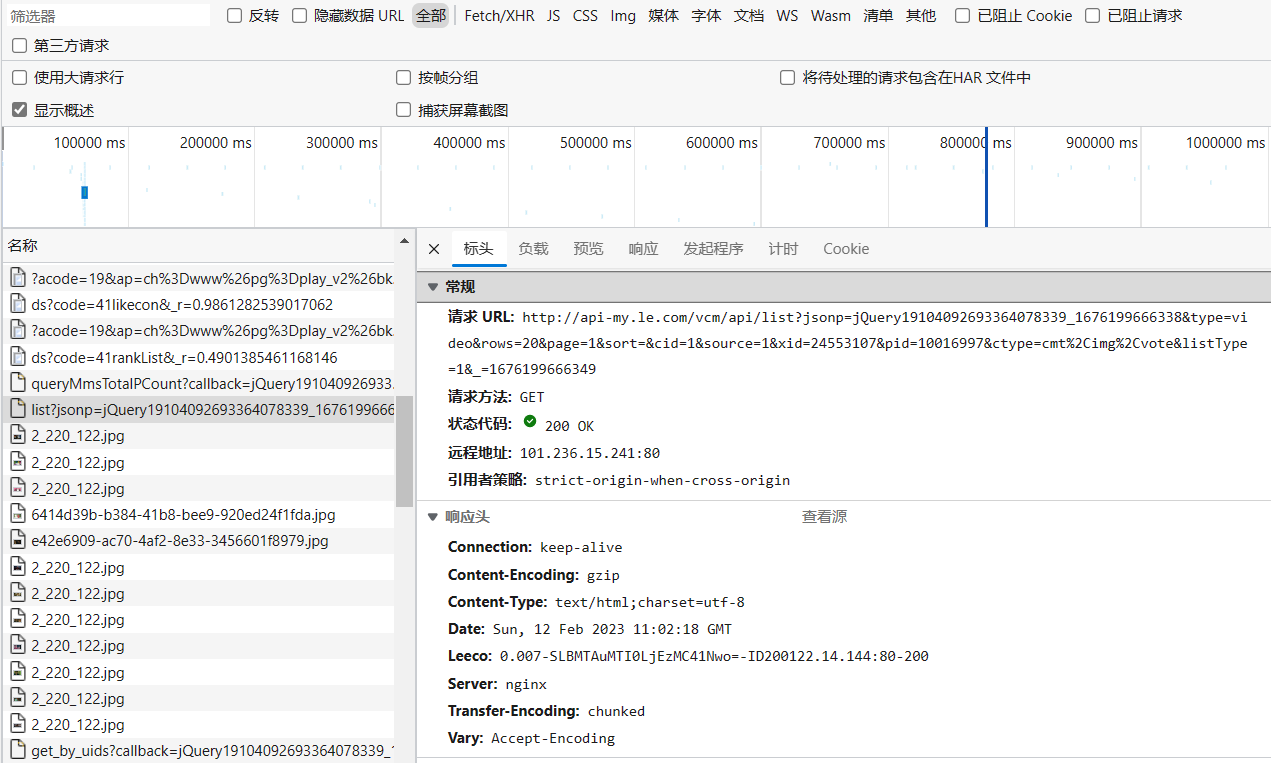
分析其请求的URL,发现评论信息通过请求URL返回,且在请求URL中需要两个参数pid和vid,这两个参数是可变的,但是我们可以在源代码中找到,于是我们就可以通过正则表达式提取出这两个参数,再请求评论信息
# -*- codeing=utf-8 -*-
# @Author:姜磊
# 人间烟火气,最抚凡人心
import requests
import json
import re
# 异步评论网址
url="http://api-my.le.com/vcm/api/list?jsonp=jQuery191020790219234869944_1659099483907&type=video&rows=20&page=1&sort=&cid=1&source=1&xid={xid}&pid={pid}&ctype=cmt%2Cimg%2Cvote&listType=1&_=1659099483914"
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.71'
}
idUrl='http://www.le.com/ptv/vplay/24553107.html'
def geturl(url,headers):
html_b=requests.get(url,headers=headers).content
html=html_b.decode()
return html
# 访问原始页面
idHtml=geturl(idUrl,headers)
# print(idHtml)
# 获取异步评论网址当中的vid与pid,其隐藏在原始html中
vid=re.search("vid: (\d+)",idHtml).group(1)
pid=re.search("pid: (\d+)",idHtml).group(1)
comment_url=url.format(xid=vid,pid=pid)
# 评论内容
html=geturl(comment_url,headers)
# print(type(html))
json_source=html[html.find('{"'):-1]
data_dict=json.loads(json_source)
# print(data_dict)
data=data_dict['data']
for single_data in data:
print(single_data['content'])